![[AI] Peaking At The Peak LLM](https://raw.githubusercontent.com/Yuma-Tsushima07/blog-imgs/main/peaking_at_the_peak_llms/Peaking_At_The_Peak_LLM_Thumbnail.png)
Intro
We are at the peak of AI being showcased anywhere and everywhere. Meaning this is a way for hackers to be creative, pentesting LLMs! In this blog post I will be showcasing on the attack vectors hackers could take to pentest LLMs.
What is an Large Language Models (LLM)?
LLM refers to Large Language Models which is a type of Artificial Intelligence program that can recognise and generate text among other tasks. LLMS are trained by using huge sets of data called “Big Data”.
LLMs usually present a chat interface to accept user input, known as a prompt. The input allowed is controlled in part by input validation rules.
What are LLMs?
LLM refers to Large Language Models which is a type of Artificial Intelligence program that can recognise and generate text among other tasks. LLMs are trained by using huge sets of data called “Big Data”.
LLMs use a type of machine learning called deep learning in order to understand how characters, words, and sentences function together.
Deep learning involves the probabilistic analysis of unstructured data, which eventually enables the deep learning model to recognize distinctions between pieces of content without human intervention.
LLMs are then further trained via tuning: they are fine-tuned or prompt-tuned to the particular task that the programmer wants them to do, such as interpreting questions and generating responses, or translating text from one language to another.
What is an AI Model?
AI models is a program which has been trained on a set of data to recognise certain patterns to make certain decisions without further human intervention. AI models can apply algorithms too relevant data inputs to achieve the tasks, or output what they have been programmed for.
Algorithmns VS Models
Algorithms
Algorithms are procedures, often described in mathematical language or pseudocode, to be applied to a dataset to achieve a certain function or purpose.
Models
Models are the output of an algorithm that has been applied to a dataset.
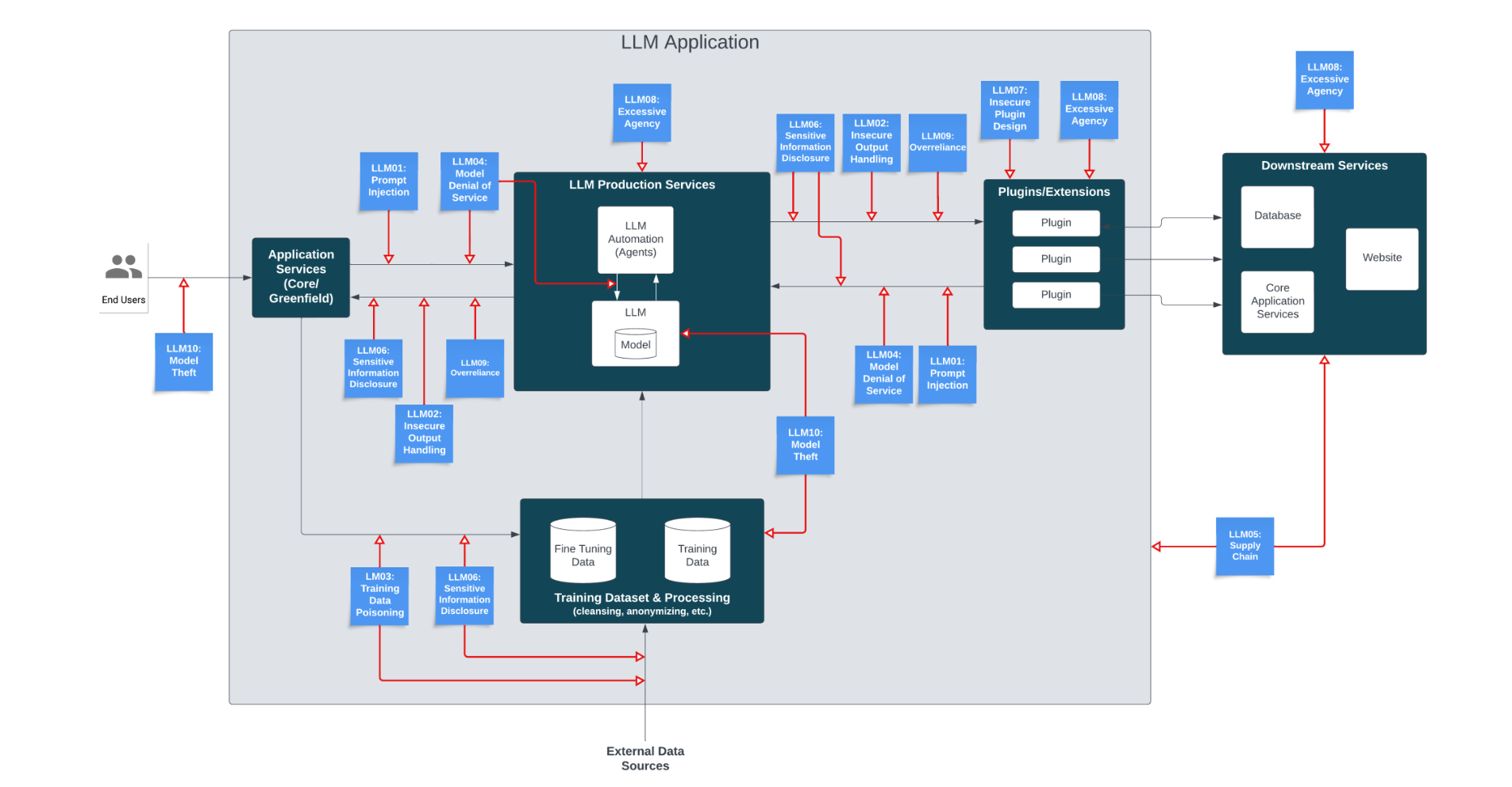
OWASP Top 10 for LLMs
LLM01: Prompt Injection
This manipulates a LLM through crafty inputs, causing unintended actions by LLM. Direct injections overwrite system prompts, where indirect ones manipulate inputs from external sources.
LLM02: Insecure Output Handling
This vulnerability occurs when an LLM output is accepted without scrutiny, exposing backend systems. Misuse may lead to severe consequences like XSS, CSRF, SSRF, privilege escalation, or remote code execution.
LLM03: Training Data Poisoning
This occurs when LLM training data is tampered, introducing vulnerabilities or biases that compromise security, effectiveness, or ethical behavior. Sources include Common Crawl, WebText, OpenWebText, & books.
LLM04: Model Denial of Service
Attackers cause resource-heavy operations on LLMs, leading to service degradation or high costs. The vulnerability is magnified due to the resource-intensive nature of LLMs and unpredictability of user inputs.
LLM05: Supply Chain Vulnerabilities
LLM application lifecycle can be compromised by vulnerable components or services, leading to security attacks. Using third-party datasets, pre- trained models, and plugins can add vulnerabilities.
LLM06: Sensitive Information Disclosure
LLMs may inadvertently reveal confidential data in their responses, leading to unauthorised data access, privacy violations, and security breaches. It’s crucial to implement data sanitisation and strict user policies to mitigate this.
LLM07: Insecure Plugin Design
LLM plugins can have insecure inputs and insufficient access control. This lack of application control makes them easier to exploit and can result in consequences like remote code execution.
LLM08: Excessive Agency
LLM-based systems may undertake actions leading to unintended consequences. The issue arises from excessive functionality, permissions, or autonomy granted to the LLM-based systems.
LLM09: Overreliance
Systems or people overly depending on LLMs without oversight may face misinformation, miscommunication, legal issues, and security vulnerabilities due to incorrect or inappropriate content generated by LLMs.
LLM10: Model Theft
This involves unauthorised access, copying, or exfiltration of proprietary LLM models. The impact includes economic losses, compromised competitive advantage, and potential access to sensitive information.
How can we detect them?
We can detect LLM vulnerabilities via these steps:
- Looking at the LLM’s inputs like prompts and training data inputs.
- Working out what data and APIs it has access to.
- Check out this new attack surface for vulnerabilities.
- Evaluate the LLM’s input validation mechanisms to ensure that they properly sanitized and validate user inputs to prevent common security vulnerabilities such as injection attacks, cross-site scripting (XSS), or command injection.
- Verify that the LLM enforces proper authorisation checks to prevent unauthorized access to sensitive resources or functionality. Test for common authorization bypass techniques, such as privilege escalation, insecure direct object references (IDOR), or broken access control.
How does LLM APIs work?
The workflow for integrating an LLM with an API depends on the structure of the API itself. When calling external APIs, some LLMs may require the client to call a separate function endpoint (effectively a private API) in order to generate valid requests that can be sent to those APIs.
This can be shown by this example:
A users sends a prompt and the LLM recogises that it needs to invoke a function and respond to a JSON object containing parameters structured according to an external API format. The client invokes the function using the provided parameters. After recieving the response. The client proceeds to process it accordingly. Subsequently, it contacts the LLM again, including the functions response as a new message. Then the LLM utilises the functions response to make a call to an external API. Finslly, the LLM summerises the outcome and presents it back to the user.
This process may pose security risk, while the LLM is initiating calls to an external API without the users knowledge. The user would prefer to recieve confirmation before the LLM proceeds to respond to the external API.
Summary
LLMs are Large Language Models and they are quite insecure. You can detect vulns via training inputs, input sanitisation, etc. They call external APIs which makes them double insecure depending if the API would be up to date or not. LLMs uses a type of machine learning called deep learning in order to understand how characters, words, and sentences function together.
Overall, LLMs have a long way to go to be secure as we are still searching for new vulnerabilities within this scope.
End Note
Bored while doing this post, mainly because there is nothing to do on my side. I guess now this is the best way to kill my boredom.
Anyways, I loved writing this blog post if you would like to contact me feel free to here.
Thanks all.